Fino ad ora si sono prese in considerazione query top-$k$ con una sola relazione $R$, tuttavia e necessario considerare anche query della forma come segue:
Il caso di studio che ha portato alla realizzazione delle prima soluzione per questa casistica e stato quello in cui le partizioni di $R$ non sono virtuali (database partizionato) detto anche il middleware scenario, definito come segue
si ha un set di sorgenti di dati
la query coinvolge due o più di queste sorgenti
il risultato si ottiene integrando in qualche modo i risultati parziali delle singole interrogazioni
flowchart TD
A[(Mediator)]
B[wrapper]
C[wrapper]
D[(source 1)]
E[(source 2)]
A -- "select * from MyCars where Price < 15000"--> B
A --"select * from MyCars where FuelConsumption < 7"--> C
B --> D
C --> E
💡
il caso del middleware scenario non e diverso dal caso delle top-$k$ join 1-1 query, con la differenza che nel caso delle query gli input sono locali, tuttavia le logiche algoritmiche sono le stesse :)
in caso di funzione di scoring MAX la query e risolvibile per mezzo dell’algoritmo $B_0$, l’idea di base e quella di recuperare i primi $k$ migliori risultati parziali da ogni sorgente (ogni accesso e detto round) e computare il risultato senza effettuare accessi random
Input:rankedlistsLj(j=1,…,m),integerk1Output:thetop-kobjectsaccordingtotheMAXscoringfunction# B is a main-memory bufferB=[]forjinrange(1,m):# the set of objects "seen" on LjObj[j]={}foriinrange(1,k):# get the best k objects from each listt=getNextLj();Obj[j].append(t.OID)ift.OIDnotinB:# adds t to the bufferB.append(t)else:# join t with the entry in B having the same OID;# for each object with at least one partial score compute MAX using the available scoresforobjectinObj:MAX(object)return#the k objects with maximum score
Il teorema di cui sopra si può applicare seguendo un principio simile a quello visto per KNNOptimal dove ad ogni step si effettua un accesso ordinato sulla lista dove $p_j$ e massimo (la più promettente)
Perche b0 non funziona con altre scoring function
#
$B_0$ non funziona con funzioni diverse dalla funzione MAX perche al termine degli accessi sequenziali non vi e nessun limite inferiore al valore della scoring function, di conseguenza un oggetto che non e stato rilevato da un accesso sequenziale puo essere il match migliore
L’algoritmo FA sfrutta la proprietà di monotonicita della funzione di scoring per recuperare i best match, data la definizione di funzione di scoring monotona come segue
L’algoritmo recupera i primi $k$ score parziali dalle $m$ liste e per ogni oggetto con uno score parziale esegue un accesso random per recuperare gli altri, per ogni oggetto computa $S$ e restituisce i record con lo score massimo
L’algoritmo risulta computazionalmente esoso in quanto non viene sfruttata la funzione di scoring per ridurre lo spazio di ricerca, e non vengono anticipati i random access
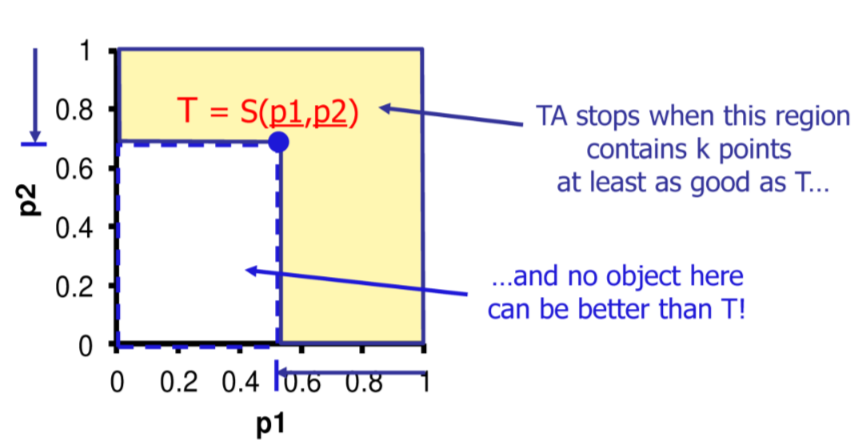
L’algoritmo TA e un miglioramento dell’Algoritmo FA, basato su threshold, in particolare
esegue in maniera combinata accessi ordinati e random
si ferma al raggiungimento di una threshold T che e un upper bound per gli oggetti non ancora visti
# Input: ranked lists lj (j=1,…,m), integer k 1, monotone scoring function s# Output: the top-k objects according to sforiinrange(1,k):Res[i]:=[null,0]forjinrange(1,m):pj:=1whileRes[k].score<T:=S(p1,p2,…,pm):forjinrange(1,m):t:=getNextLj()o:=t.OID# perform random accesses to retrieve the missing partial scores for oifS(o):=S(p1(o),…,pm(o))>Res[k].scorethen:# {remove the object in Res[k]; insert [o,S(o)] in Res}# return Res
L’algoritmo scandisce le liste fino a che la funzione di costo computata sui valori letti $S(p_1,p_2,...p_m)$ non e inferiore dello score dell’ultimo elemento del risultato (che e il peggiore risultato corretto)
Per computare correttamente le performance di TA si considerano i costi di comunicazione con il client secondo la seguente funzione di costo:
$$
cost = SA*C_{SA} +RA*C_{RA}
$$
che considera costi di accessi sequenziali e randomici, i parametri $C_{SA},C_{RA}$ rappresentano il costo di singole letture sequenziali e ordinate, questi possono essere molto diversi a seconda degli scenari,
in caso di risorse web tipicamente si ha che $C_{RA} \gt\gt C_{SA}$
ma sono possibili risorse in cui non e possibile eseguire letture sequenziali $C_{SA} = \infty$
TA risulta essere instance optimal secondo la seguente definizione
data una classe di algoritmi $A$ e una classe $D$ di input un algoritmo $a \in A$ e instance optimal rispetto a $A$ e $D$ se e vero che per qualunque $B \in A$ e $DB \in D$ si ha
$$cost(a,DB) = O(cost(B,DB))$$
dato il modello di costo di cui sopra nel caso in cui $C_{RA} >0$ ovvero il caso reale si ha che il costo di TA che si arresta al passo $X$ e:
$$
cost(TA,DB) = m*X*C_{SA} + (m-1)X*m*C_{RA}
$$
Assumendo il caso peggiore in cui per ogni oggetto visto sia necessario effettuare il massimo numero di accessi random, il ratio di ottimalita risulta essere
$$
m + m(m-1)\frac{C_{RA}}{C_{SA}}
$$
❗
Che in caso di costi randomici alti puo diventare proibitivo
L’algoritmo NRA e pensato per quando non e possibile effettuare accessi randomici, restituisce comunque le $k$ risposte corrette ma i punteggi di score potrebbero essere errati
L’idea e quella di mantenere per ogni oggetto visto per mezzo della scansione sequenziale un lower e upper bound per la funzione di costo
$S^-(O)$ computato ponendo a 0 (o al minimo valore possibile) tutti gli score parziali di $O$ non visti per mezzo della scansione sequenziale
$S^+(O)$ computato ponendo $p_j(O) = p_j$ (il minimo dei valori visti per quella lista) tutti gli score parziali di $O$ non visti per mezzo della scansione sequenziale
Gli elementi trovati vengono mantenuti in una lista $B$ ordinati per valori di lowerbound
L’algoritmo termina quando le prime $k$ posizioni di $B$ contengono i valori migliori ovvero
$$
S^+(o^{'}) \leq S^-(o) \forall o^{'} \notin Res, o \in Res
$$
💡
Ovvero tutti i valori visti non in res hanno un valore massimo di $S$ minore di quelli nel risultato
In caso siano necessari i valori di scoring e sufficiente estendere NRA eseguendo tante scansioni sequenziali fino a che tutti gli oggetti non vengono trovati
L’idea dietro all’algoritmo CA e quella di ridurre il costo degli accessi randomici eseguendo le letture ogni $\frac{C_{RA}}{C_{SA}}$ rounds, per il resto l’algoritmo si comporta come NRA.
$B_0$, MaxOptimal, FA, TA, NRA, NRA*, CA al confronto
#
Algoritmo
scoring function applicabili
accesso ai dati
note
$B_0$
MAX
ordinato
instance optimal
MaxOptimal
MAX
ordinato
instance optimal
FA
monotone
ordinato e randomico
costo indipendente da $S$
TA
monotone
ordinato e randomico
instance optimal
NRA
monotone
ordinato
instance optimal,wrong scores
NRA*
monotone
ordinato
instance optimal, exact scores
CA
monotone
ordinato e randomico
instance optimal ratio di ottimalita indipendente da $\frac{C_{RA}}{C_{SA}}$ in alcuni casi