regression
It’s a supervised task used on numeric variables with the objective of minimize the error of the prediction using the other variables for the prediction
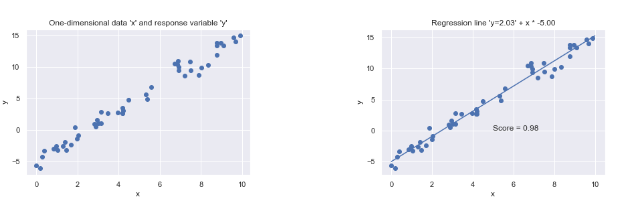
linear regression
given a data set $X$ with $N$ rows and $D$ columns:
- $x_{i}$ is a $D$ dimensional data element response vector $y$ with $N$ values $y_{i}$
- $w$ is a $D$-dimensional vector of coefficients that needs to be learned
so the relation between the $yi$ element and the $xi$ elements is modeled
$$ y_{i} = w^T*x_{i} \space \forall i \in [1…N] $$ so the forecast is given by
$$ y^f = X*w^T $$
quality indicators
- Mean of the observed data
$$ y^{avg} = \frac{1}{N}*\sum_{i}{yi} $$
- Sum of squared residuals $SS_{res}$
$$ SS_{res} = \sum_{i}({yi-yi^f})^2 $$
- Total sum of squares $SS_{tot}$
$$ SS_{tot} = \sum_{i}({yi-yi^{avg}})^2 $$
- Coefficient of determination
$$ R^2 = 1 - \frac{SS_{res}}{SS_{tot}} $$
the Coefficient of determination compares the chosen model with that of a horizontal straight line
if the model does not follow the trend of the data the $R^2$ value can be also negative
when the number of feature is high overfitting is possible
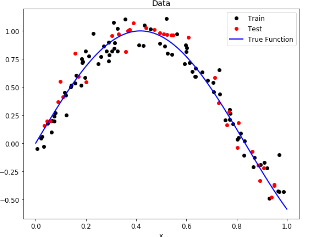
polynomial regression
the target is influenced by a single feature and the relationship can’t be describe by a straight line