fp-growth
The Apriori Alg. needs to generate the candidates sets, whose number can be really high! The FP-Growth algorithm consists on finding shortest patterns to chain with suffixes. FP-Growth uses a compact representation of the DB via a FP-Tree, on which a recursive approach is used, following the “divide et impera” principle.
how it works
- Data are scanned in order to find the max support for every single item. Non-frequent item are discarded. Frequent items are sorted by decreasing support.
- A second scan is done to build the FP-Tree. When the first transaction is read, the A and B nodes are generated with frequency counting = 1.
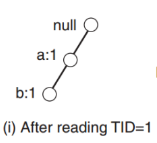
- When the second transaction is reaa new set containing the B, C and D nodes are created, each one with its relative path starting from the null node. Then, the subtree created during step 1) is linked to the just generated one. The two paths do not overlap because of their different prefix.
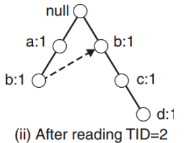
- If an overlapped path is found (it has the same prefix as a node, let’s suppose, A), the counting of the node A is increased by 1.
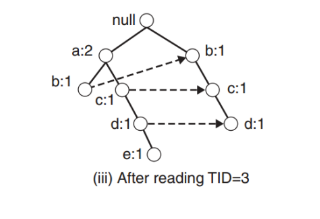
- The algorithm continues untill the last transaction.
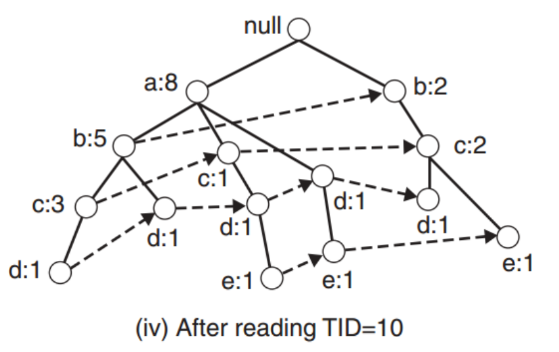
The tree size is often lower than the dataset one, but it depends on the transactions orientation.
searching in the fp-tree
Then, FP-Growth procedes with a **bottom-up strategy:
- The research procedure goes from the less frequent item to the most frequent one. FP-Growth scans the tree in search of itemset ending with the desired search item (es. D).
- Then look for the only paths that contain the D element. This search is sped up with a pointer data structure.
- So the subquestion that contains all the itemsets that end in D and that are frequent has to be built. The research is done by evaluating all possible combinations found that include D and that exceed $minSup$ in a divide-and-conquer logic, starting from the leaves to the root.